Bevezetés
Merült már fel bennetek az, hogy dinamikusan hozzatok létre adatbázisokat egy-egy újonnan regisztrált szervezet vagy ügyfél számára? Magamtól ritkán jut eszembe ilyesmi, de a legutóbbi projektnél pont ilyen funkcionalitást kért a megrendelőnk. Amellett, hogy az alábbi kitételeket is teljesíteni kellett ?:
- A kód legyen Java nyelven.
- A keretrendszer Spring boot legyen.
- Legyen egyszerű az adatbázis migráció verzióról verzióra.
- Bizonyos entitások egy közös adatbázisban legyenek, bizonyos entitások pedig ügyfelenként külön adatbázisokban.
- Futás időben lehessen szabályozni, hogy az új ügyfelek adatbázisa melyik adatbázis szerveren jöjjön létre.
Hogy miért is volt erre szükség?
Egyrészt, az ügyfelek megnyugtatására, hogy az ő adataik istibizti nincsenek egy olyan adatbázisban, ahol más ügyfél adatai is szerepelnek.
Másrészt, egyszerűen tudjuk az adott ügyfélhez tartozó adatokat törölni, és kizárólag azt (pl.: GDPR-ra hivatkozva). Kisebb legyen a rizikó, hogy valami kimarad a végtelen idegen kulcson keresztüli sql deletekhez képest.
Harmadrészt, ha az ügyfél a saját adatait át szeretné helyezni egy másik helyszínre (mondjuk Kínába, vagy épp ő szeretné biztosítani az adatainak a tárolását), akkor is egyszerűbb dolgunk legyen.
Sorolhatnám, de inkább lássuk a megvalósítást.
Terv
Az alábbi ábra mutatja, mi volt a terv az adatok tárolására:
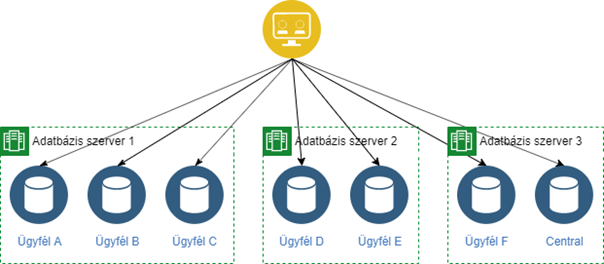
A sárga kör az alkalmazásunk, a zöld keretek mysql adatbázis szerverek, a bennük található kék körök pedig az ügyfelekhez tartozó adatbázisok (későbbiekben tenant-ok), valamint a central elnevezésű közös adatbázis.
Egyértelmű, hogy nyilván kell tartanunk az adatbázis szervereket és az adatbázisokat is olyan módon, hogy azok futásidőben is bővíthetők legyenek. Ezeket az információkat a central adatbázisban tervezem tárolni, magát a central adatbázis elérését pedig az alkalmazás konfigurációjában.
Megvalósítás
A megvalósításban egy egyszerüsített alkalmazást fogok bemutatni, ami nem tartalmazza a megrendelőnek átadott szoftver üzleti logikáját.
Gradle
Az alkalmazásban használt külső függőségeket gradle segítségével használtam:
plugins {
id 'org.springframework.boot' version '2.1.8.RELEASE'
id 'io.spring.dependency-management' version '1.0.8.RELEASE'
id 'java'
}
group = 'hu.lazloz'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '12'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'mysql:mysql-connector-java'
implementation 'org.flywaydb:flyway-core'
}Projekt felépítése
A projektet négy fő részre osztottam: * A config az adatbázisok és a hozzájuk tartozó kapcsolatok konfigurációit tartalmazza. * Az entity tartalmazza az összes adatbázis entitást. * A repository a könnyebb adatbázisműveletek érdekében volt használva. * A resources pedig az alkalmazás konfig fájlját és az adatbázisokhoz tartozó verziózott szkripteket tartalmazza.
A teljes fájlstruktúra az alábbi ábrán látható:
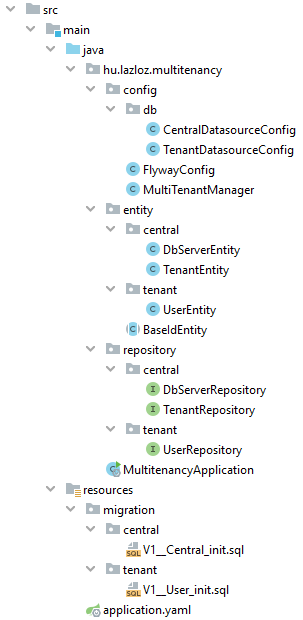
Ezen jól látható a felépítés és az is, hogy milyen osztályokat tartalmaznak az egyes részek.
Central config
A központi adatbázishoz tartozó datasource-t a CentralDatasourceConfig.java osztály tartalmazza, ebben először létrehoztam egy Hikari datasource-t, ami lehetőséget biztosít arra, hogy a kapcsolatokat egy pool-ban tárolja, így a kapcsolatépítés költségét sok esetben megspórolhatjuk (további leírást ezen a linken találsz).
private final DataSourceProperties properties;
@Value("${spring.datasource.hikari.maximum-pool-size}")
private int maximumPoolSize;
@Primary
@Bean(name = "centralDatasource")
public HikariDataSource getCentralDataSource() {
log.debug("getCentralDataSource");
HikariDataSource defaultDataSource = DataSourceBuilder.create()
.type(HikariDataSource.class)
.driverClassName(properties.getDriverClassName())
.url(properties.getUrl())
.username(properties.getUsername())
.password(properties.getPassword())
.build();
defaultDataSource.setMaximumPoolSize(maximumPoolSize);
return defaultDataSource;
}Erre építve létrehoztam egy EntityManagerFactory beant, ami a hu.lazloz.multitenancy.entity.central könyvtárban létrehozott entitások kezeléséért fog felelni (és csak azokért).
@Primary
@Bean(name = "centralEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean entityManagerFactory(EntityManagerFactoryBuilder builder,
@Qualifier("centralDatasource")
DataSource dataSource) {
return builder
.dataSource(dataSource)
.packages("hu.lazloz.multitenancy.entity.central")
.persistenceUnit("central")
.build();
}Ehez pedig létrehoztam egy tranzakció menedzsert is, az alábbiak szerint.
@Bean(name = "centralTransactionManager")
public PlatformTransactionManager transactionManager(@Qualifier("centralEntityManagerFactory")
EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}Végezetül az osztályra az alábbi annotációkat tettem, amivel meghatároztam az entitásokhoz tartozó repository könyvtár helyét is. Így kényszerítem ki az alkalmazásból, hogy ha a centralhoz tartozó repositoryt használom, akkor a centralhoz konfigurált datasource-t, ennél fogva a central adatbázist használja.
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories(entityManagerFactoryRef = "centralEntityManagerFactory",
transactionManagerRef = "centralTransactionManager",
basePackages = {"hu.lazloz.multitenancy.repository.central"})Tenant config
A tenant adatbázisokhoz tartozó datasource-t a TenantDatasourceConfig.java osztály tartalmazza. Ennek bizonyos elemei hasonlítanak a centralnál leírtakhoz. Itt is létre kellett hozni egy datasource-t, hozzá egy entityManagerFactory-t, abból egy tranzakció mendezsert, és az osztályon található annotációk is azonosak. Az egyik különbség, hogy az entitások helyének a hu.lazloz.multitenancy.entity.tenant könyvtárat határoztam meg, a repositoryknak pedig a hu.lazloz.multitenancy.repository.tenant könyvtárat. Továbbá a centrallal ellentétben itt az AbstractRoutingDataSource osztály felüldefiniált példányát használtam.
A megvalósítás során több változót is defináltam.
A currentTenant az aktuálisan kiválasztott tenant kódját fogja jelenteni (egy prefix + a kód a mysql schema name-et határozza meg, ami tulajdonképpen a kívánt adatbázis lesz). Ezt használjuk a megfelelő connection kiválasztására:
private final ThreadLocal<Long> currentTenant = new ThreadLocal<>();A currentServer az aktuálisan kiválasztott datasource kulcsa lesz, ami a kiválasztott adatbázishoz tartozó szervert fogja jelenteni:
private final ThreadLocal<Long> currentServer = new ThreadLocal<>();A tenantDataSources -ban tároljuk az adatbázis szerverekhez tartozó datasource-okat. Ennek a kulcsa lesz kiválasztva a currentServer -ben. A könnyebb módosíthatóság kedvéért tartom ebben a változóban is, noha ugyanezt tárolja a tenantDatasource bean is (lásd lentebb).
private final Map<Object, Object> tenantDataSources = new ConcurrentHashMap<>();Magát a létrehozandó tenantDatasource beant is (ami az AbstractRoutingDataSource példányra fog mutatni) kiemelem egy változóba a könnyebb hozzáférhetőség érdekében:
private AbstractRoutingDataSource multiTenantDataSource;
Végül itt van maga a datasource létrehozása a korábban említett felülírásokkal:
@Bean(name = "tenantDatasource")
public DataSource getStoreDataSource() {
multiTenantDataSource = new AbstractRoutingDataSource() {
@Override
protected Object determineCurrentLookupKey() {
return currentServer.get();
}
@Override
public Connection getConnection() throws SQLException {
Connection connection = determineTargetDataSource().getConnection();
connection.setCatalog(TENANT_DB_PREFIX + currentTenant.get().toString());
return connection;
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
Connection connection = determineTargetDataSource().getConnection(username, password);
connection.setCatalog(TENANT_DB_PREFIX + currentTenant.get().toString());
return connection;
}
};
multiTenantDataSource.setTargetDataSources(tenantDataSources);
multiTenantDataSource.afterPropertiesSet();
return multiTenantDataSource;
}Az osztályban továbbá létrehoztam egy metódust, ami az aktuális tenantDataSources listát bővíti, ha nem találja benne a lekérdezett szervert:
public void createNewDatasourceIfNotExistAndGet(DbServerEntity server) {
log.trace("createNewDatasourceIfNotExist > serverId:{}", server.getId());
HikariDataSource dataSource = (HikariDataSource) tenantDataSources.get(server.getId());
if (dataSource == null) {
dataSource = DataSourceBuilder.create()
.type(HikariDataSource.class)
.driverClassName(properties.getDriverClassName())
.url(server.getUrl())
.username(properties.getUsername())
.password(properties.getPassword())
.build();
dataSource.setMaximumPoolSize(maximumPoolSize);
tenantDataSources.put(server.getId(), dataSource);
multiTenantDataSource.afterPropertiesSet();
}
}Ezek alapján már körvonalazódhat az olvasó számára, hogy nem egy piskóta receptet próbálok leírni, de van még pár dolog hátra.
Adatbázis séma verziózás
Így, hogy az alkalmazás több adatbázishoz is kapcsolódik, egy fokkal bonyolultabb az adatbázis sémák frissen tartása, mint általában. Ahhoz, hogy az alkalmazással összhangban változzanak verzióról verzióra az adatbázis tábla sémák is, flyway -t használtam.
A FlywayConfig osztályban az alábbiak szerint valósítottam meg a séma frissítések kezelését:
@Bean(name = "flyway")
public Flyway migrateDefaultDB(@Qualifier("centralDatasource") DataSource dataSource) {
log.info("migrateCentral");
Flyway flyway = Flyway.configure()
.locations("db/migration/central")
.dataSource(dataSource)
.schemas(DEFAULT_SCHEMA)
.load();
flyway.migrate();
return flyway;
}
@Bean
public Boolean migrateAllTenantDB(TenantRepository tenantRepository, MultiTenantManager multiTenantManager) {
log.info("migrateAllTenants");
tenantRepository.findAll().forEach(tenant -> {
multiTenantManager.setCurrentTenant(tenant);
migrateTenantDB(multiTenantManager.getCurrentTenantDatasource(), tenant.getId());
});
return true;
}
static void migrateTenantDB(DataSource dataSource, Long tenantId) {
String schema = TENANT_DB_PREFIX + tenantId;
Flyway flyway = Flyway.configure()
.locations("db/migration/tenant")
.dataSource(dataSource)
.schemas(schema)
.load();
flyway.migrate();
}A legnagyobb trükk ott van, hogy a migrateAllTenantDB esetén már használom a central.tenant táblájában szereplő listát arra, hogy végig iteráljak a tenant adatbázisokon a frissítés érdekében, így az összes dinamikusan kezelt tenant adatbázis is könnyűszerrel frissíthető az alkalmazás indulásakor.
Új tenantok létrehozása és meglévők használata futás időben.
Az utolsó kulcs része a rendszernek, hogy hogyan is tudunk műveleteket végrehajtani a central és a tenant adatbázisokon, valamint hogy hogy adhatunk futásidőben új tenant adatbázist a meglévőkhöz. Ennek megvalósítása érdekében létrehoztam a MultiTenantManager vezérlő osztályt, amin keresztül ez mind megvalósítható.
Első körben létrehoztam egy ChainedTransactionManager Bean-t, ami a TenantConfig és CentralConfig fejezetekben írt tranzakció menedzsereket egyesíti:
@Primary
@Bean(name = "transactionManager")
public ChainedTransactionManager transactionManager(
@Qualifier("centralTransactionManager") PlatformTransactionManager ds1,
@Qualifier("tenantTransactionManager") PlatformTransactionManager ds2) {
return new ChainedTransactionManager(ds1, ds2);
}Ennek használatával ha az adott hívási láncban ki van választva egy tenant, akkor a metódusra helyezett @Transactional annotációkban nem kell kitölteni a value értékét, mivel az alapértelmezett tranzakció menedzser a transactionManager nevű Bean lesz.
Az új tenant létrehozása valamelyest komplikáltabb üzleti logikát követ, mivel több dologra is figyelni kell: * Az új tenanthoz van-e kiválasztható adatbázis szerver, ha nincs legyen használva az alapértelmezett (configban definiált) * Az új tenenthoz tartozó entitás kerüljön mentésre a central adatbázisba * Az új tenanthoz tartozó migrációs scriptek fussanak le (hozza létre a megfelelő sémákat) * A kiválasztott adatbázis szerver be van-e töltve a AbstractRoutingDataSource -ok közé.
@Transactional(value = "centralTransactionManager")
public void createNewStoreDatabase(TenantEntity tenantEntity) {
log.info("setCreateAndSetTenant");
try {
DbServerEntity server = getDbServer();
tenantEntity.setDbServerId(server.getId());
tenantRepository.save(tenantEntity);
DataSource dataSource = new SimpleDriverDataSource(new Driver(), server.getUrl(), properties.getUsername(), properties.getPassword());
FlywayConfig.migrateTenantDB(dataSource, tenantEntity.getId());
tenantDatasourceConfig.createNewDatasourceIfNotExistAndGet(server);
} catch (SQLException e) {
log.error("An error occured in datasource removing:", e);
throw new RuntimeException();
}
}
private DbServerEntity getDbServer() {
DbServerEntity server;
List<DbServerEntity> chooseableServers = dbServerRepository.findByChooseableTrue();
if (chooseableServers.size() == 0) {
server = createDefaultDbServerIfNotExist();
} else {
server = chooseableServers.get(0);
}
if (server == null) {
throw new RuntimeException("Not found chooseable DbServer");
}
return server;
}
private DbServerEntity createDefaultDbServerIfNotExist() {
DbServerEntity server = null;
List<DbServerEntity> allServer = dbServerRepository.findAll();
if (allServer.size() == 0) {
server = new DbServerEntity("DEFAULT", defaultUrl, true);
dbServerRepository.save(server);
}
return server;
}A szemfülesek észrevehetik, hogy míg a migrációhoz egy SimpleDriverDataSource-t használok addig az AbstractRoutingDatasource-ba HikariDataSource-okat raktam a Tenant Config fejezetben. Ennek oka, hogy a migrációnál lévő kapcsolatokat a migráció után nem tudtam lecsatlakoztatni, amikor Hikari-t használtam, és a unit tesztek során elértük a MySql connection limitjét. A fenti megoldással viszont ezzel nem volt probléma. #magic #hack ?
Végül a tenant kiválasztására két metódust is használhat a másik szinten lévő service vagy dao osztály (a másodikat használta a flywayConfig tenant migrációja is):
@Transactional(value = "centralTransactionManager")
public TenantEntity setCurrentTenant(Long tenantId) {
log.info("setCurrentTenant > tenantId:{}", tenantId);
Optional<TenantEntity> tenantEntity = tenantRepository.findById(tenantId);
if (tenantEntity.isPresent()) {
return setCurrentTenant(tenantEntity.get());
} else {
throw new RuntimeException("Store not found tenantId: " + tenantId);
}
}
@Transactional(value = "centralTransactionManager")
public TenantEntity setCurrentTenant(TenantEntity tenantEntity) {
log.info("setCurrentTenant > tenantId:{}", tenantEntity.getId());
refreshDatasourceForStore(tenantEntity);
currentTenant.set(tenantEntity);
tenantDatasourceConfig.setTenant(tenantEntity.getDbServerId(), tenantEntity.getId());
return tenantEntity;
}Ezek a metódusok azt is szemléltetik, hogy ha egy metódusban tranzakciót akarunk kezelni, de korábban nem lett kiválasztva tenant (mondjuk bármelyik setCurrentTenant metódussal), akkor meg kell adni, hogy használja a centralhoz tartozó tranzakciós menedzsert a value megadásával.
Végszó
A leírás teljessége kedvéért létrehoztam egy minimalista git projektet is a fentebb említett megvalósítások mentén, így a gyakorlatban is kipróbálhatóak az említett módszerek: https://gitlab.com/krutakl/spring-db-multitenancy
Ha a leírásban vagy a projektben valami kivetnivalót találtok, akkor írjatok e-mailt a lazloz92@gmail.com -ra, hozzatok létre issuet vagy merge requestet és lehetőségeimhez mérten igyekszem hamar reagálni rájuk.